

The HubSpot Pipedrive integration question comes up in two very different situations. Either your team is running both CRMs at the same time as a sales agency using Pipedrive while the parent company runs HubSpot, for example and you need data to move between them reliably. Or someone in leadership looked at the HubSpot vs Pipedrive comparison and decided it’s time to consolidate. Those are two completely different problems and they need different solutions.
A HubSpot Pipedrive integration connects the two CRM platforms to sync contacts, companies, deals, and activities in real time, letting both systems operate from the same underlying data without manual re-entry. A Pipedrive to HubSpot migration is a one-way move: you extract your CRM history from Pipedrive, map it to HubSpot’s data model, and shut Pipedrive down.
We have handled both scenarios across dozens of mid-market B2B implementations as a HubSpot Diamond Solutions Partner with custom integration accreditation. This guide gives you the honest breakdown of what works, what breaks, and how to decide which path is right for your team.
Free estimator
Know what your HubSpot project costs before the first call.
Select your services and get a transparent price range in minutes. No sales call needed to get a number.
Connect HubSpot to your ERP, billing platform, or database field mapping, custom logic, and support included.
Pipelines, workflows, email templates, and reporting configured for how your team actually works.
Live, role-based sessions with recordings and written guides built around a custom plan for your team.
HubSpot Partner
Client retention
Platforms integrated
Key Takeaways
- The native HubSpot Pipedrive connector syncs contacts and basic deal data but has documented limits around dropdown fields, custom objects, and activity types.
- Running both CRMs in parallel long-term creates data governance risk. It works best as a temporary bridge while a migration is planned.
- A Pipedrive to HubSpot migration requires a field mapping workbook, deduplication pass, association preservation strategy, and rate limit-aware extraction scripts.
- Pipedrive moved to token-based API rate limiting in December 2024, fully rolled out by May 2025. Migration scripts built before then need re-architecting.
- Integrate IQ delivers HubSpot Pipedrive integrations and migrations in 8 weeks from kick-off for standard scope. Complex builds with large historical datasets run longer.
Why Teams Run HubSpot and Pipedrive at the Same Time
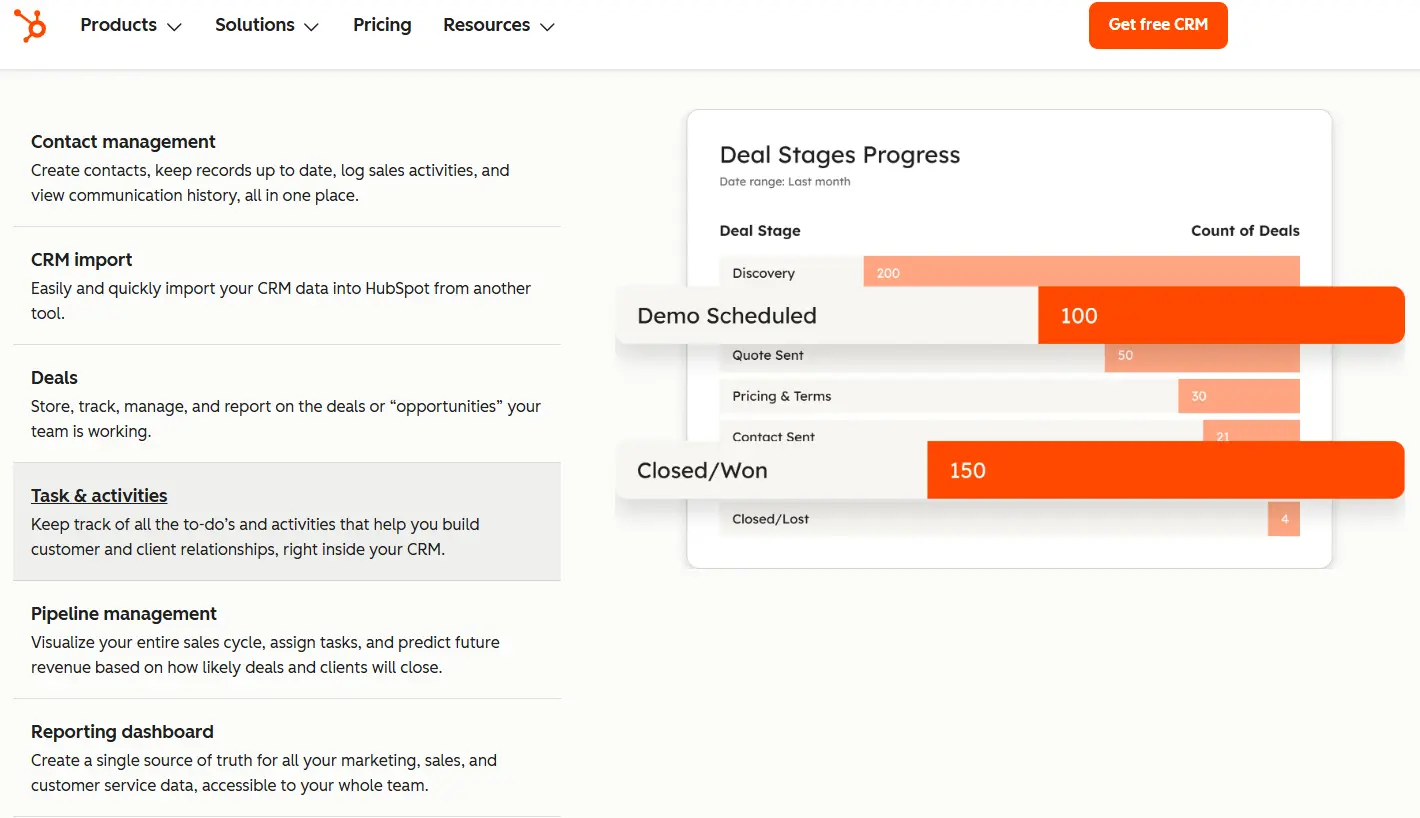
The most common scenario: a company uses HubSpot for marketing and internal sales, while an external sales agency or a recently acquired subsidiary runs Pipedrive. Both teams need to see the same contacts and deal progression without logging into each other’s systems.
A second scenario: a company mid-migration. They’ve bought HubSpot started onboarding, but Pipedrive is still live with six months of active pipeline inside it. The integration keeps both systems current while the team completes the cutover.
A third scenario, which is rare but real: one team genuinely prefers Pipedrive’s visual pipeline UX for sales execution while marketing insists on HubSpot’s automation and attribution. The integration lets each team stay in their preferred tool while leadership gets unified reporting.
All three scenarios are valid in the short term. None of them are good long-term architecture. Two CRMs means two sources of truth, two sets of permission rules, two sync points that can drift, and double the data governance overhead. Every integration we build for parallel CRM usage includes a clear conversation about the end state.
Turn HubSpot Into A Real-Time SMS Engine with
Message IQ
Two-Way Conversations
Shared Team Inbox
Automation Triggers
Advanced Reporting
Compliance Tools
-
98%
SMS read within 3 min -
78%
Buy from first responder -
21×
More likely to qualify
3–5 min avg response
$45–$50 ROI / $1
*MessageIQ is an IntegrateIQ product – built natively for HubSpot by the same team.
What the Native HubSpot Pipedrive Integration Actually Does

HubSpot’s Operations Hub includes a native data sync connector for Pipedrive. It’s available in the HubSpot Marketplace from the Pipedrive side too. Setup takes minutes. But ‘set up in minutes’ doesn’t mean ‘production-ready in minutes.’
Here’s what syncs natively:
- Contacts and People records (bidirectional)
- Companies and Organizations (bidirectional)
- Deals and Pipedrive Deals (bidirectional, with stage mapping)
- Basic standard fields: name, email, phone, company name, deal value
Here’s what the native connector doesn’t handle well:
- Dropdown field to dropdown field mapping the native sync engine can’t map two dropdown fields directly to each other. The documented workaround is mapping a dropdown to a single-line text field, which only works one-directionally.
- Activity type sync: Sales activities created in Pipedrive don’t fully sync back to HubSpot. Only one activity type reliably transfers, which is a known limitation surfaced repeatedly in HubSpot Community threads.
- Custom objects: If you are using HubSpot custom objects or Pipedrive custom data fields beyond standard contact/deal properties, the native connector doesn’t reach them without Operations Hub Professional at minimum.
- Association preservation the relationships between contacts, companies, and deals don’t always survive a native sync correctly. A contact associated with three deals in Pipedrive may come through with broken or missing associations in HubSpot.
- Historical activity logs past notes, calls, and meeting records from Pipedrive don’t migrate through the native sync connector. It syncs current state, not history.
For simple, real-time contact and deal syncing between two teams that genuinely need both CRMs active at once, the native connector works. For any use case that requires complete data fidelity, historical records or custom field coverage, you’re building custom.
HubSpot Pipedrive Integration Methods: Which One Fits Your Scenario
| Factor | Native Connector (HubSpot Data Sync) | Custom API Build / iPaaS (Workato, Make) |
| Setup Time | Minutes to hours | 3–8 weeks |
| Contact + Company Sync | Yes | Yes, with full field control |
| Deal Sync | Basic, with stage mapping | Full, including line items and custom stages |
| Dropdown-to-Dropdown Fields | Not supported natively | Supported with transformation logic |
| Activity / Engagement Sync | Partial (one activity type only) | Full, with type mapping and filters |
| Custom Objects | Not supported | Supported |
| Historical Data | No | Yes, with extraction and transformation scripts |
| Association Preservation | Unreliable | Reliable with explicit mapping |
| Ongoing Maintenance | Low | Medium (requires monitoring and updates) |
| Best For | Simple, real-time contact sync between two teams | Complex workflows, full data parity, migration bridges |
Field Mapping Between HubSpot and Pipedrive: Where It Gets Technical
Field mapping is the part teams consistently underestimate. HubSpot and Pipedrive store similar data in structurally different ways. Getting this wrong means your sync produces garbage, and garbage in a CRM is worse than no data because it looks legitimate.
Object Naming Differences
Pipedrive calls them ‘Persons’ and ‘Organizations.’ HubSpot calls them ‘Contacts’ and ‘Companies.’ Deals exist in both but use different stage definitions. Before you map a single field, you need a canonical naming document that resolves these differences across both systems.
Field Authority: Master, Mirror, or Derived
For every field that exists in both systems, you need to define one of three states:
- Master : One system owns this field, the other accepts updates from it. Example: HubSpot owns Lifecycle Stage, Pipedrive reads it.
- Mirror: Truly bidirectional, last-write-wins. Use this sparingly. It only makes sense for non-critical fields where both teams legitimately update the same value.
- Derived: A field calculated from other fields, never synced directly. Example: HubSpot’s Lead Score is calculated in HubSpot from engagement data, not pulled from Pipedrive.
Without explicit field authority definitions, you get sync conflicts where both systems write to the same field and overwrite each other in a loop. We’ve cleaned up more than a few integrations that were corrupting data silently because nobody defined who owned what.
Lifecycle Stage to Pipeline Stage Mapping
HubSpot’s Lifecycle Stage model Subscriber, Lead, MQL, SQL, Opportunity, Customer needs a deliberate mapping to Pipedrive’s pipeline stages. The promotion rules matter too: who or what triggers a contact to move from Lead to MQL? Marketing automation? A sales activity? A manual update? Define these in your field mapping workbook before any sync goes live.
Picklist and Dropdown Alignment
If your Pipedrive Lead Source dropdown has seven values and HubSpot’s has twelve, you need a transformation layer that resolves mismatched values before they sync. Letting ‘Website Contact Form’ from Pipedrive land as an unrecognized value in HubSpot breaks segmentation, attribution, and every workflow that depends on that field.
What Breaks in a HubSpot Pipedrive Integration and Why
Sync Conflicts from Bidirectional Writes
When both systems can write to the same field without a defined authority rule, last-write-wins creates a conflict loop. HubSpot updates a contact’s phone number. Pipedrive overwrites it three minutes later with the old value. This is invisible until someone notices the data is wrong, which is usually months after go-live.
Owner ID Mismatches
HubSpot assigns contact and deal ownership by user ID. Pipedrive does the same. The mapping between user accounts in both systems needs a maintained lookup table. When a sales rep leaves and their Pipedrive account gets deactivated, deals owned by that user produce routing errors in HubSpot. This happens to teams that set up the integration and never maintain the owner map.
Pipedrive’s 2024 Rate Limit Change
Pipedrive moved to token-based API rate limiting starting December 2024, with full rollout to existing customers by May 2025. Each API endpoint now carries a token cost based on computational complexity. A simple contact GET is cheap. A search query or a complex deal update costs significantly more. Integration scripts built before this change weren’t architected for token budget management and break under load especially if sales reps are working in Pipedrive at the same time the sync is running.
Activity Type Gaps
The native connector only syncs one Pipedrive activity type back to HubSpot. If your sales team logs calls, emails, meetings, and tasks in Pipedrive, only one category of those activities appears in HubSpot. This breaks engagement timelines, activity reporting, and any workflow in HubSpot that triggers on sales activity.
Authentication Breaks
OAuth tokens for HubSpot expire. Pipedrive API tokens tied to a specific user account break when that user leaves. Service account credentials, not named user credentials, need to own the integration connection. This is the most preventable failure mode and also the most common.
When ‘Integration’ Should Actually Be ‘Migration’: The Decision Framework
Running HubSpot and Pipedrive in parallel makes sense as a temporary state. It starts breaking down as a long-term strategy when:
- Your team spends meaningful time reconciling data discrepancies between the two systems
- Leadership can’t get a single clean view of pipeline because deals live in two places
- HubSpot workflows need contact or deal data that only lives in Pipedrive
- The integration maintenance cost (monitoring, conflict resolution, field mapping updates) exceeds the cost of migrating properly
- You’re paying for both platforms and the combined licensing cost is significant
The inflection point for most teams is when HubSpot starts doing things Pipedrive can’t marketing automation, multi-touch attribution, service ticketing, revenue reporting and the integration becomes a workaround rather than an architecture. That’s when migration is the right call.
Pipedrive to HubSpot Migration: What It Actually Takes
A Pipedrive to HubSpot migration moves your CRM history contacts, companies, deals, activities, notes, and custom fields into HubSpot’s data model cleanly, with associations preserved and no data loss. Here’s how we scope and execute it.
Step 1: Audit and Scoping
Before writing a single extraction script, document every object in Pipedrive: Persons, Organizations, Deals, Activities, Notes, Products, and custom fields. Count records per object type. Identify which historical records are worth migrating archived deals from five years ago with no associated contacts probably aren’t. Decide on migration scope before you start, not after.
Step 2: Field Mapping Workbook
Map every Pipedrive field to its HubSpot equivalent. Flag fields with no direct mapping and document your resolution: does it become a custom property, a workflow-generated value, or does it get dropped? This workbook is the source of truth for the entire migration. Every discrepancy caught here saves hours of post-migration cleanup.
Step 3: Data Cleaning Before Extraction
Deduplicate Pipedrive before the migration, not after. Duplicate records in Pipedrive become duplicate records in HubSpot with broken associations that take significant effort to untangle. Run your deduplication pass in the source system while you still have Pipedrive’s native deduplication tools available.
Step 4: Extraction with Rate Limit Management
Since Pipedrive’s December 2024 token-based rate limit change, extraction scripts need explicit token budget management. Burst limits apply on a rolling two-second window per API token. Rapid-fire requests trigger 429 errors; persistent abuse triggers 403 responses from Cloudflare. Your extraction script needs retry logic, token cost awareness, and backoff handling or your migration stalls mid-run with partial data.
Step 5: Association Preservation
This is the part that separates a clean migration from a CSV dump. A contact associated with three companies and two deals in Pipedrive needs those associations to survive the move to HubSpot. A CSV export transfers records; it doesn’t transfer relationships. Your migration script needs to explicitly rebuild associations in HubSpot using the extracted relationship data from Pipedrive.
Step 6: Sandbox Validation
Run the migration in a HubSpot sandbox before touching production. Validate that contacts look right, deals have the correct owners and stages, activities appear on the correct contact timelines, and custom property values match the source data. Sales, RevOps, and finance each need to sign off on their data use cases before the production cutover.
Step 7: Production Cutover
Agree on a cutover window. Freeze Pipedrive data entry for a defined period while the final extraction and import runs. Set clear expectations with your sales team about when they can start working in HubSpot exclusively. Post-cutover, monitor HubSpot data quality for two weeks and have a rollback plan documented even if you expect not to need it.
HubSpot Pipedrive Integration and Migration: Realistic Timelines
| Engagement Type | Standard Timeline | Complex Build | Key Complexity Driver |
| Native sync setup (contacts + deals only) | 1–3 days | 1 week | Custom field volume, owner mapping |
| Custom API integration (full data parity, running parallel) | 4–6 weeks | 8–10 weeks | Activity types, custom objects, association logic |
| Pipedrive to HubSpot migration (under 50K records) | 6–8 weeks | 10–12 weeks | Historical activity depth, custom field count |
| Migration with large dataset (50K–500K records) | 10–12 weeks | 14–16 weeks | Rate limit management, dedup complexity, validation scope |
Frequently Asked Questions
Does HubSpot integrate with Pipedrive natively?
Yes. HubSpot’s Operations Hub includes a native Pipedrive data sync connector. It handles bidirectional contact, company, and deal syncing for standard fields. It has documented limitations around dropdown-to-dropdown field mapping, activity type syncing, and custom objects. For most teams that need simple, real-time record syncing between both platforms, the native connector is the right starting point. Teams with complex field structures, historical data requirements, or custom objects need a custom API build.
Can HubSpot and Pipedrive sync in real time?
The native connector syncs with a few minutes of latency, not true real-time. Some iPaaS platforms like Workato support near-real-time sync through webhook triggers. Custom API builds can achieve near-real-time for high-priority events like deal stage changes, with scheduled batch syncs for lower-priority field updates. True simultaneous write scenarios still carry conflict risk regardless of sync speed.
What data can you move from Pipedrive to HubSpot?
A well-executed migration moves Persons to Contacts, Organizations to Companies, Deals to Deals, Activities to Engagements, Notes to Notes, and custom fields to custom HubSpot properties. The challenge is association preservation, making sure contacts remain linked to their companies and deals after the move and activity transformation, since Pipedrive and HubSpot store activity data differently. Historical email threads and file attachments require additional handling beyond standard migration tools.
How long does a Pipedrive to HubSpot migration take?
For standard scope under 50,000 records, no complex custom objects, clean source data Integrate IQ delivers in 6–8 weeks from kick-off. Larger datasets, heavily customized Pipedrive instances or migrations requiring transformation of five-plus years of activity data run 10–16 weeks. Timeline is driven by data quality in Pipedrive more than by record count alone.
What happens to Pipedrive API rate limits during a migration?
Pipedrive moved to token-based API rate limiting in December 2024. Each API endpoint now carries a token cost proportional to its computational complexity. Migration scripts that ignore this hit 429 rate limit errors mid-extraction. Scripts built before this change need re-architecting. Critically, your token budget is shared across all users and all active integrations on the account simultaneously so if your team is still working in Pipedrive while the migration runs, their activity competes with the extraction script for the same token pool.
Should I integrate HubSpot with Pipedrive or migrate from Pipedrive to HubSpot?
Integrate if you have a genuine long-term need for both systems to operate concurrently typically a partner or agency scenario where different teams own different CRMs. Migrate if the goal is to consolidate onto HubSpot and Pipedrive is being retired. Running both indefinitely carries data governance overhead that compounds over time. Most teams that start with an integration end up executing the migration within twelve to eighteen months anyway.
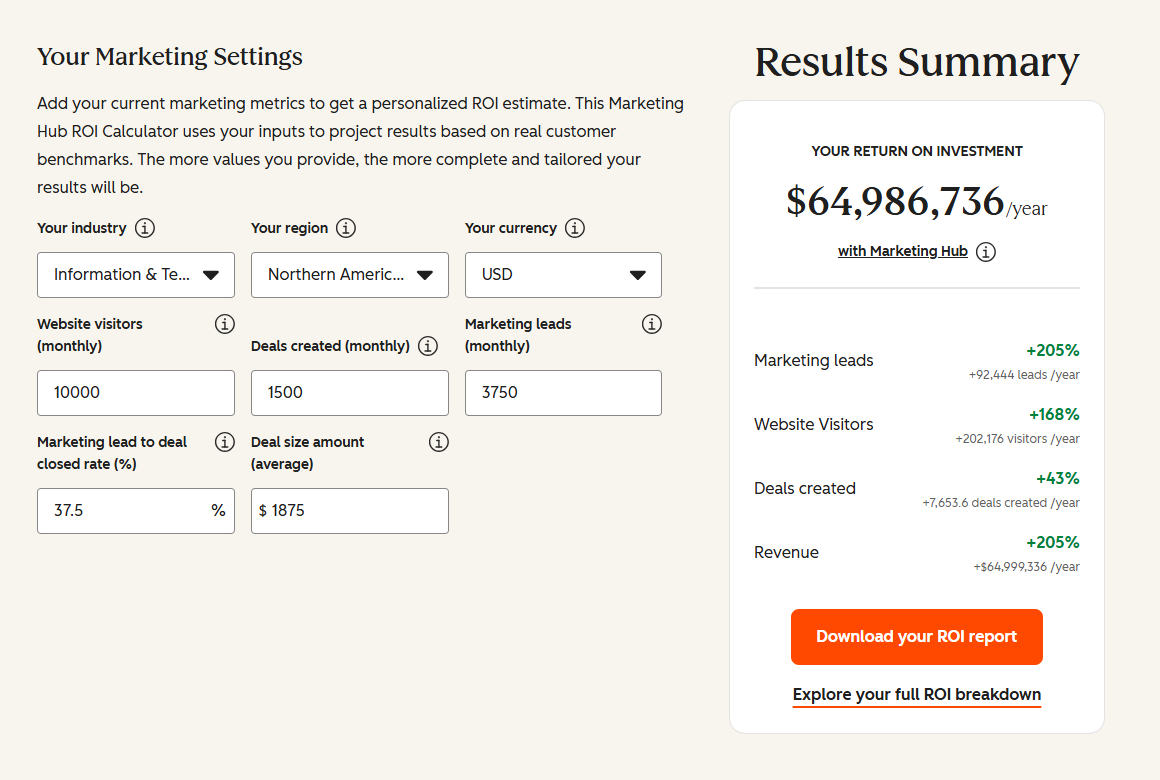
See your 12-month revenue impact with HubSpot CRM
Enter your current numbers — visitors, leads, deal size — and get a personalized projection based on real HubSpot customer benchmarks.
Start with the Right Architecture
Whether you are syncing HubSpot and Pipedrive for a parallel-use scenario or ready to move off Pipedrive entirely, the decisions you make upfront on field mapping, sync direction, and data governance determine whether this works cleanly or becomes a recurring cleanup project.
As a HubSpot Diamond Solutions Partner with 300+ platforms integrated and 98.5% client retention, we scope these engagements to surface the decisions that matter before a line of code runs. We deliver in 8 weeks from kick-off for standard builds. Start with a scoping call at integrateiq.com/contact-us or review how we approach integration architecture at integrateiq.com/our-hubspot-integration-process.

Table of Contents
- Key Takeaways
- Why Teams Run HubSpot and Pipedrive at the Same Time
- What the Native HubSpot Pipedrive Integration Actually Does
- HubSpot Pipedrive Integration Methods: Which One Fits Your Scenario
- Field Mapping Between HubSpot and Pipedrive: Where It Gets Technical
- What Breaks in a HubSpot Pipedrive Integration and Why
- When 'Integration' Should Actually Be 'Migration': The Decision Framework
- Pipedrive to HubSpot Migration: What It Actually Takes
- HubSpot Pipedrive Integration and Migration: Realistic Timelines
- Frequently Asked Questions
- Start with the Right Architecture
